
曾经在一个图站上给QQ机器人爬点图片,结果没过一个月AI绘画火起来后,图站更新了Cloudflare来反爬虫,想了各种办法来绕开反爬虫都没起效,一时间还把我脑子给干冒烟了。我就突发奇想,有什么可以自己操作浏览器进行数据交互,触发反爬虫机制时就可以人工控制完成验证,而且开发难度又不会很高的东西。后来一查还真有,可以使用Python+Selenium模块来完成我上述的所有想法。
在咕咕很长时间后的今天,也就是开发完表格自动化之后,我又想起了网页自动化,可能是触发了我的自动化之魂(MC后遗症),驱使着我去折腾它,于是就有了现在的尝试。
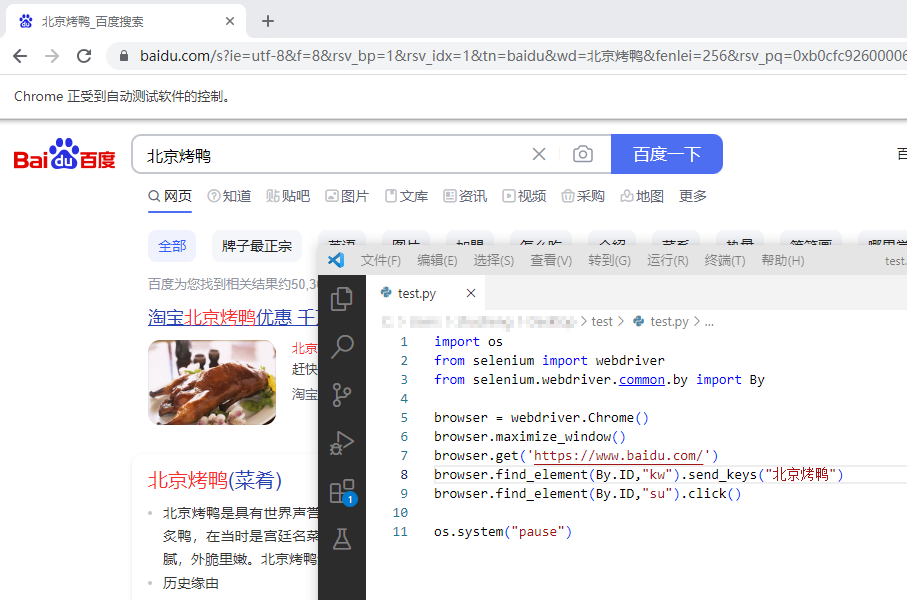
体验下来,Selenium模块还是挺强大的,模拟一次百度搜索仅需要五行代码,简单粗暴。配合之前学习的xlwings模块,应该能对我之前繁琐的(网页-表格)数据抄录工作有极大的帮助,实现其半自动化或全自动化的数据处理。等哪天有空了,立个目标来练习下这个项目开发。哦对,还有我的网页爬虫练习。